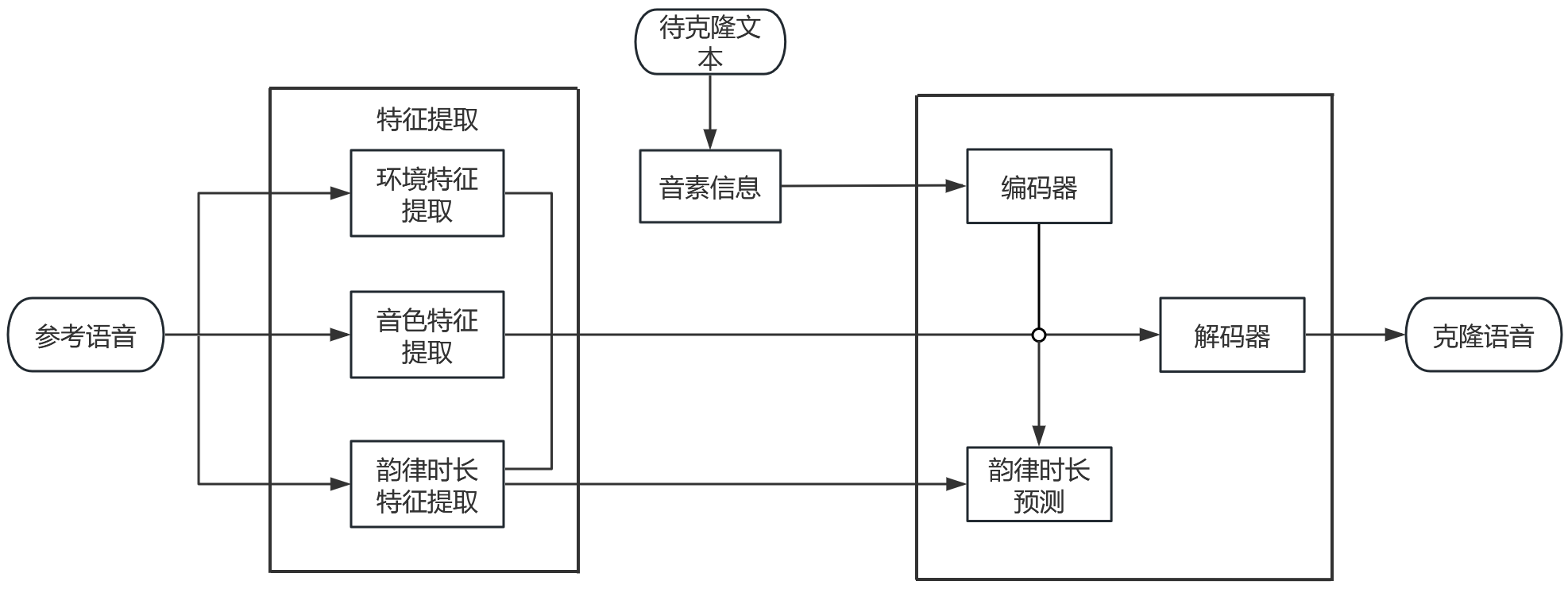
项目简介:
声纹识别技术广泛应用于身份验证、客户服务、法律等领域,但传统声纹识别需要为每个用户建立个性化声纹模型,耗时且昂贵。声纹克隆系统的核心任务是生成与特定说话人相似的声音,使得难以分辨真实声音与克隆声音。本项目基于生成对抗网络,它由生成器和鉴别器组成。生成器负责生成克隆声音,而鉴别器则试图区分真实声音和克隆声音。基于说话人特征建模:通过提取说话人的声学特征,如声道长度、共振峰等,来构建声纹克隆系统。并在推理阶段加入中文韵律预测模型,可以帮助声纹克隆系统更好地理解和模拟中文语言的语法、结构和语境,从而生成更自然、流畅的声音。声纹克隆的声音将保留原始声音的语气、音调和声音特征,系统可根据需要生成特定说话人的声音,适用于不同场景,如语音合成、角色扮演等,可以提供更自然、个性化的声音,改善用户体验。声纹克隆系统已经在语音合成领域取得了巨大成功,它在虚拟助手和虚拟主持人应用中得到广泛使用,为用户提供了更加个性化的语音互动体验。此外,声纹克隆系统在广播和影视行业也发挥了关键作用,可以轻松实现声音模仿和角色扮演,使得广播和电视节目更加多样化和生动。随着深度学习技术的不断进步,声纹克隆系统将进一步完善,扩展到更多领域,为用户提供更多可能性。